- Facebook22
- Threads
- Bluesky
- Total 22
The efficiency and power with which we quantify and analyze society has increased astonishingly in less than a lifetime. But our ability to explain, predict, let alone improve society has hardly grown at all.
Around the time when I was born (1967), you collected information about people by talking to them, writing what they said on paper, and then possibly transferring the records to punched cards. You statistically analyzed the data by hand, or, if you were lucky enough to have access to a computer, by running the cards through a program that took many hours just to generate descriptive statistics, such as means. You published results for other people to read, but you could only analyze raw data that you had physical access to. You had to think carefully about every hypothesis and query, because calculation was laborious. Statistical techniques were relatively limited, and more elaborate techniques would have been too hard to execute.
Since then, the following changes have occurred:
- Information is easily digitized and widely shared, so people around the world can analyze any single dataset.
- Data are collected electronically, so there is no need for manual data-entry.
- Statistical techniques have become far more sophisticated, so we can now understand how A relates to B holding many other variables constant, even if data are nested, corrupt, or oddly sampled.
- Because statistical analysis is now conducted quickly and easily by computers and computational power has expanded exponentially, we can test as many hypotheses as we want.
- Instead of taking representative samples, we can now sometimes sweep up all the data. For example, some states have longitudinal records on every child in their schools. Facebook knows every user’s friends and timeline.
- Individual records are being tagged consistently, so that one can search for answers to the same question on multiple surveys. ICPSR is leading the way toward tagging surveys with metadata. For instance, searching the ICPSR database for survey questions about parents volunteering in schools, one finds 338 results from different surveys. That instantly produces a kind of “meta-dataset” that can be analyzed.
- Qualitative information is also being coded and tagged: not just transcripts but audio and video files that retain tone of voice, body-language, accent. At some point, qualitative datasets will be archived and meta-tagged in the same way as surveys, so that we can combine the depth of interviews with the breadth of multiple-choice instruments.
And yet … do we understand society much better than we did in 1967? Borrowing from a previous post about the exponential increase in the quantity of information exchanged, I’d suggest that these are the trends:
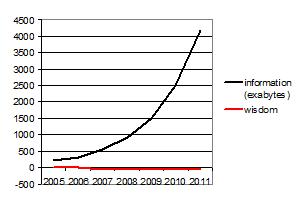
Perhaps we already knew the important truths in 1967: for example, that if you fail to invest in kids, their lives will turn out worse. Perhaps in those days, we understood better how to take political action so that policies would change in the ways that social science recommended. In other words, maybe we can describe society better today but have less influence on it.
Maybe we are lost in trivial or even spurious results. If you test 100 hypotheses, 5% of false ones will look true by sheer chance, so you will generate five falsehoods.
Sometimes I wonder if we have created a Borgesian nightmare, an increasingly detailed map of the world at 1:1 scale, which is not a guide to reality but just a second world to get lost in.
Thank you, Peter. I have often wondered the same… but I am being increasingly surprised by the changeable nature of people’s views when new info is applied. Perhaps if we focused our educational energy on helping people to filter without prejudice and debate information with sound foundations, as well as to simply exchange it, then it will continue to benefit us.
Like much of technology, I think we will see adaptation around processing on a human level. I believe the visceral nature of caring about others will always have the power to overcome fear and prejudice that is the root of division, exploitation, and violence. Today’s tool are neutral in this, nevertheless humans will be humans.